We live in the information age, when information travels around the world, processed by our computers and smartphones. The data is usually compressed, which greatly reduces the cost of its storage and transfer.
Some tasks, such as video transmission, would be practically impossible without compression, in this case reducing the file size even up to a thousand times. Hence, the development of data compression is very important, and so is the reduction of the computational cost of compression, which involves increasing speed and reducing energy consumption, both by giant database centres and our smartphones. These key parameters have recently been significantly improved thanks to the coding technology developed at the Jagiellonian University. Since 2014, it has been replacing old methods in compressors of major IT companies, including Apple, Facebook and Google.
What is data compression?
Data compression consists in singling out relevant information from a file and its optimal encoding. It takes advantage of the fact that rare events carry more information than the frequent ones. For instance, an event whose occurrence probability is 1/2 carries one bit of information, whereas an event whose occurrence probability is 1/8 carries as many as three bits. The processing of a sequence of such events (symbols) of variable information content into a sequence of bits (zeros and ones) is the heart of data compression, formally known as the entropy encoding, as the compression level is limited by Shannon’s entropy.
The basic way of processing data is Huffman coding, introduced in 1952. The symbol is directly encoded as a sequence of bits, e.g. A as 010. Thanks to its simplicity, it has become the heart of most compressors we are using when:
- taking pictures or viewing images (image compression) – e.g., jpg, png,
- listening to music, talking on phone (sound compression) – e.g., mp3,
- using general purpose compression – e.g., zip, rar,
- and many other situations, e.g., when using pdf and doc documents.
 Huffman coding is computationally inexpensive, but it is not optimal due to approximation. For instance, the symbol with 0.99 probability carries only 0.014 bit information, whereas Huffman coding must use as least one bit to encode it. This suboptimality (inaccuracy) was mended in 1960 in the arithmetic coding, which originated circa 1960, but started to be widely used as late as after 2000, due to the higher computational costs, among other factors. Practically speaking, it reaches an optimum (Shannon entropy). It is currently used in video compression, without which single movies would require hundreds of gigabytes.
Huffman coding is computationally inexpensive, but it is not optimal due to approximation. For instance, the symbol with 0.99 probability carries only 0.014 bit information, whereas Huffman coding must use as least one bit to encode it. This suboptimality (inaccuracy) was mended in 1960 in the arithmetic coding, which originated circa 1960, but started to be widely used as late as after 2000, due to the higher computational costs, among other factors. Practically speaking, it reaches an optimum (Shannon entropy). It is currently used in video compression, without which single movies would require hundreds of gigabytes.
Huffman’s coding and arithmetic coding replaced by tANS and rANS
The above compromise between Huffman coding (cheap but suboptimal) and arithmetic coding (optimal but expensive) ended due to the introduction of the currently used family of coding, called Asymmetric Numeral Systems (ANS). It was started by the staff member of the JU Institute of Computer Science Dr Jarosław Duda, who introduced several variants of the ANS during the years 2006-2014. “The first variant of this coding was discussed in my MSc thesis in Physics in 2006. Its publication attracted interest from people who specialise in data compression. In late 2007, I introduced the variant that is most commonly used today (the so-called tANS – tabled ANS). After a few years’ break, the topic re-emerged in 2013, when first implementations appeared (the method provided the basis for a programme). They showed a significant advantage of ANS over the standard methods. Since that moment, things started to develop very quickly. I introduced a very distant variant (the so-called rANS – range ANS), which is becoming more and more popular. ANS-based compressors, whose creators have included such giants as Apple, Facebook or Google, started to emerge", explained Dr Duda.
Usually, the entire information in the compressor is finally processed by entropy coding. It used to be a costly bottleneck, which often determined the speed of compression. The ANS allowed to reduce this cost multiple times and motivated researchers to seek further optimisations. As a result, Huffman coding was speeded up three times during the last 3 years. Yet, this significant leap seems modest when compared to the thirtyfold acceleration of detailed coding enabling better compression.
During the last decade, the increase in frequencies of processors have practically stopped due to a technological barrier. The example of ANS suggests that the basic methods can still leave a lot of room for improvement. This is a lesson that it is always worthwhile to keep on seking new solutions.
What does the new coding give us?
From the perspective of electronic devices users, the ANS coding enabled major acceleration and file size reduction for compressors that have been built since 2014, and already widely used. Since mid-2015, it is a default information encoding option for Apple devices (iPhone, Mac), which use Apple LZFSE compressor. In August 2016, Facebook presented its free Zstandard compressor (zstd, version 7-Zip), which is beginning to replace the widely used zlib (zip files), for instance, in The Guardian daily, due to much better parameters (the chart is presented below; the dots correspond to the selected compression option, from 1 to 22 for zstd).
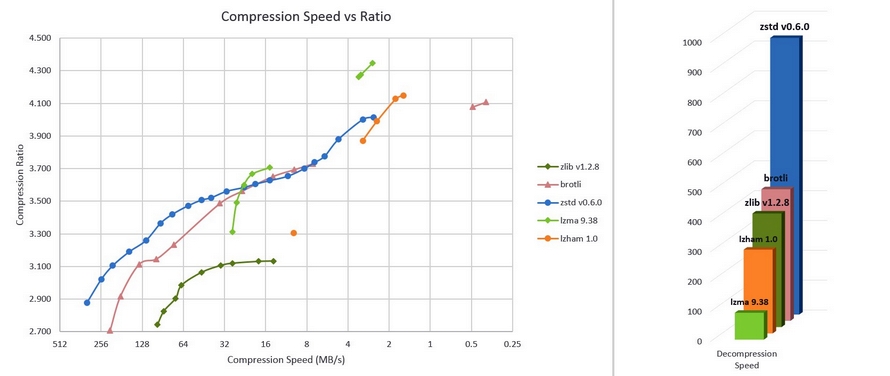
- zstd is over two times faster in decompression than standard zlib, irrespective of the selected option (bar chart)
- during the compression (line graph) zstd is about 3-5 times faster for a similar compression level (how many times it reduced the file), or allows much better compression.
Another variant of this coding (rANS) significantly improved the efficency in, for instance, the DNA compressor CRAM 3.0 of the European Bioinformatics Institute – and texture compression on GPU (e.g. for games and virtual reality). It is also used in a development version of the free video compressor AV1, developed by the so-called Alliance for Open Media (which includes Google, Intel, Microsoft, Amazon, Netflix, Cisco, AMD, ARM, and NVidia), to be used in Youtube, Netflix, and other services.
Original text: www.nauka.uj.edu.pl